什么是物理地址?
物理地址就是内存单元的绝对地址,物理地址0x0000就表示内存条的第一个存储单元,0x0010(16进制)就表示内存条的第17个存储单元,一个存储单元是1byte(8bit)。
你问为什么是1byte?
一个内存条是由若干个黑色的内存颗粒构成的。每一个内存颗粒叫做一个chip。
每个chip中又叠了若干bank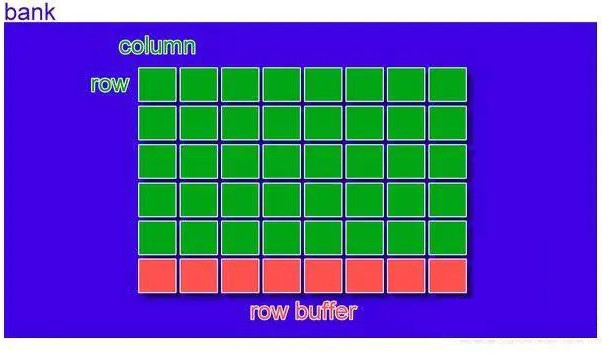
在每个bank内部,就是电容的行列矩阵结构了,每一个元素有8个小电容,存储8个bit,也就是一个字节。
什么是线性地址和虚拟地址?
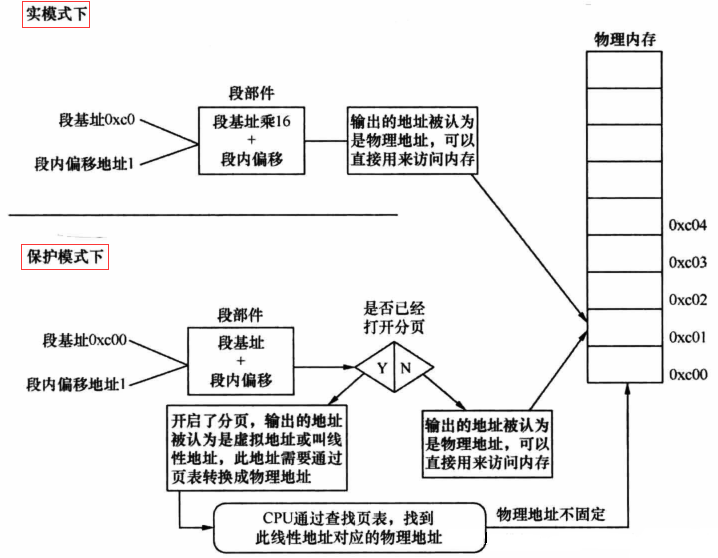
在80286系列以前,CPU只支持实模式操作模式。16位寄存器想要对20位地址线进行寻址,使用分段机制,段基址(16位) x 16(左移4位) + 段内偏移地址(4位)就是物理地址了。
这样的好处是所见即所得,程序员指定的地址就是物理地址,物理地址对程序员是可见的。同时也带来了一些问题:
1) 无法支持多任务。
2) 程序的安全性无法得到保证。
(根本原因就是一个程序直接修改了其他程序的内存,导致崩溃)
80286系列则是被设计来解决这些问题,段式访存得到的改进,原来段基址+段内偏移得到的地址不再是实际的物理地址,而是被称作为线性地址,要经过一个转换层转换才变成一个物理地址。这种CPU操作模式就被称为保护模式了。保护的是:分清楚各个程序使用的存储区域,不允许随便跨界访问。
80286系列之后就进入32位CPU时代了,32位寄存器可以直接访问32位地址总线。但是在保护模式下,地址仍然采用“段地址:偏移地址”的方式来表示。
段值仍然由原来的16位的cs、ds等寄存器表示,但是此时它们仅仅是一个索引,这些个索引指向一个数据结构的表项,表项中详细定义了一个段的起始地址、界限、属性等内容,这个数据结构,叫做GDT(其实还可能是LDT),GDT中的每一个表项,叫做描述符。
这里我们就详细看一下保护模式的寻址方式吧。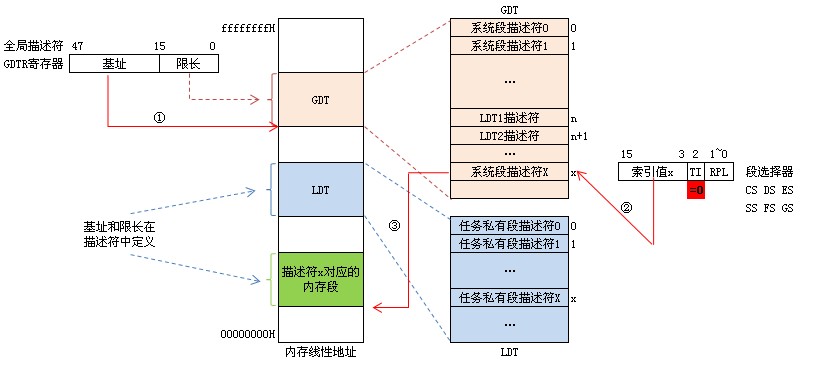
1) 寻址时,先找到gdtr寄存器,从中得到GDT的基址。
2) 有了GDT的基址,又有段寄存器中保存的索引,可以得到段寄存器“所指”的那个表项,即所指的那个描述符。
3) 得到了描述符,就可以从描述符中得到该描述符所描述的那个段的起始地址。
4) 有了段的起始地址,将偏移地址拿过来与之相加,便能得到最后的线性地址。
5) 有了线性地址,经过变换,即可得到相应的物理地址。
保护模式虽然解决了内存不被跨界访问,但是其也带来了新的问题,那就是内存碎片。
首先我们了解一下内存碎片为何产生:
首先假设我们有10B内存:
| ID | 首地址 | 尾地址 | 长度 | 状态 |
|---|---|---|---|---|
| 0 | 0 | 9 | 10 | 空闲 |
当程序申请一个长度为3的内存空间后:
| ID | 首地址 | 尾地址 | 长度 | 状态 |
|---|---|---|---|---|
| 0 | 0 | 2 | 3 | |
| 1 | 3 | 9 | 7 | 空闲 |
当程序再申请一个长度为2,以及长度为4的内存空间后:
| ID | 首地址 | 尾地址 | 长度 | 状态 |
|---|---|---|---|---|
| 0 | 0 | 2 | 3 | |
| 1 | 3 | 4 | 2 | |
| 2 | 5 | 8 | 4 | |
| 3 | 9 | 9 | 1 | 空闲 |
此时,只剩1个可用空间。如果这时程序再来申请长度大于1的空间,就申请不了,也就是内存不够。
现在,释放掉ID=1的空间:
| ID | 首地址 | 尾地址 | 长度 | 状态 |
|---|---|---|---|---|
| 0 | 0 | 2 | 3 | |
| 1 | 3 | 4 | 2 | 空闲 |
| 2 | 5 | 8 | 4 | |
| 3 | 9 | 9 | 1 | 空闲 |
我们发现,现在可用内存空间为3,但是,这3个空闲空间,并不是连续的。
所以,如果程序现在申请长度为3的内存空间,同样会申请不了,会出现内存不够。我们把这种情况,称之为内存碎片。
那内存碎片怎么解决呢?于是就有了分页机制,接下来我们详细讲一下分页:
首先,把物理内存,按照某种尺寸,进行平均分割。比如我现在以2个内存单位,来分割内存,也就是每两个连续的内存空间,组成一个内存页:
| 地址 | 页ID | 状态 |
|---|---|---|
| 0 | 0 | 空闲 |
| 1 | ||
| 2 | 1 | 空闲 |
| 3 | ||
| 4 | 2 | 空闲 |
| 5 | ||
| 6 | 3 | 空闲 |
| 7 | ||
| 8 | 4 | 空闲 |
| 9 |
| ID | 使用的内存页ID |
|---|---|
现在,程序申请长度为3的内存空间,不过由于现在申请的最小单位为页面,而一个页面的长度为2,因此现在需要申请2个页面,也就是4个内存空间。你看,这就浪费了1个内存空间。
| 地址 | 页ID | 状态 |
|---|---|---|
| 0 | 0 | |
| 1 | ||
| 2 | 1 | |
| 3 | ||
| 4 | 2 | 空闲 |
| 5 | ||
| 6 | 3 | 空闲 |
| 7 | ||
| 8 | 4 | 空闲 |
| 9 |
| ID | 使用的内存页ID |
|---|---|
| 0 | 0,1 |
接着,程序再申请长度为1,长度为2的空间:
| 地址 | 页ID | 状态 |
|---|---|---|
| 0 | 0 | |
| 1 | ||
| 2 | 1 | |
| 3 | ||
| 4 | 2 | |
| 5 | ||
| 6 | 3 | |
| 7 | ||
| 8 | 4 | 空闲 |
| 9 |
| ID | 使用的内存页ID |
|---|---|
| 0 | 0,1 |
| 1 | 2 |
| 2 | 3 |
释放掉ID=1,内存页ID为2的那条内存空间信息:
| 地址 | 页ID | 状态 |
|---|---|---|
| 0 | 0 | |
| 1 | ||
| 2 | 1 | |
| 3 | ||
| 4 | 2 | 空闲 |
| 5 | ||
| 6 | 3 | |
| 7 | ||
| 8 | 4 | 空闲 |
| 9 |
| ID | 使用的内存页ID |
|---|---|
| 0 | 0,1 |
| 2 | 3 |
现在,就出现了之前的情况:目前一共有4个内存空间,但是不连续。
不过,因为现在是分页管理机制,因此,现在仍然可以继续申请长度为4的内存空间。
没有碎片,能够尽量地全部用完空间。但仔细想想,这种优势背后,也是需要付出大量代价的。
分页的方式下,程序需要记录内存页ID,每次使用时,需要从内存页ID翻译成实际内存地址,多了一次转换。
而且这种模式,会浪费一些内存,比如上面申请3个内存空间,实际分配了2个页面共4个内存空间,浪费了1个内存空间。
还有一个要注意的地方,这个时候”段基址+段内偏移地址”经过段部件处理后得到的线性地址就不再是物理地址了,而是虚拟地址了。
从下图我们能够清楚的看出来我们最后的线性地址表示的是页表的地址,而不是物理地址了。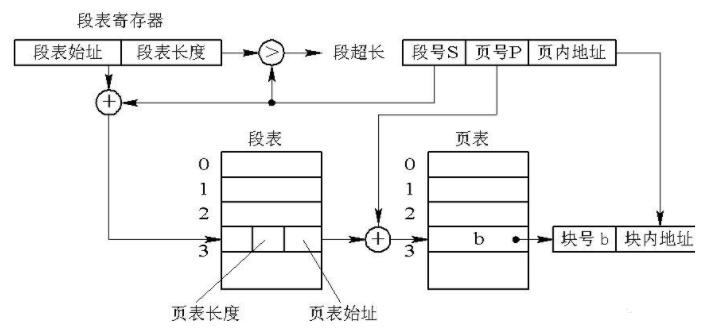
什么是逻辑地址和有效地址?
无论CPU在什么模式下,段内偏移地址又称为有效地址或者逻辑地址(只是叫法不一样罢了),例如实模式下mov ax, [0x7c00],0x7c00就是逻辑地址(或有效地址),但这条指令最终操作的物理地址是DS*16+0x7c00。
Linux最初就是在32位的80386系列上设计的,并且没有使用分段机制,所以在Linux上逻辑地址和线性地址就是一回事了。
总结
一图以概括: